EP9 - 隱私和使用體驗該怎麼取捨?
Podcast 連結
本集內容大綱
隱私包含的範圍不只有個人資料,其他資料像是你喜歡的品牌、你的搜尋瀏覽紀錄或是你的聊天紀錄也都是隱私包含範疇。
哪些資訊會被搜集?
以收聽 Podcast 為例:
- 訂閱者、收聽者數量
- 聽眾的性別、年紀、國家分布、使用的裝置統計
- 每集節目聽眾聽了多少,有沒有整集聽完
各大科技巨頭所搜集關於你的資訊: TruePeopleSearch 所整理各大科技公司所搜集的資訊 - What Information Are Giant Tech Companies Collecting From You?
搜集資料的目的
- 產品改善:分析使用者的行為模式,來觀察產品設計上是不是有問題、有沒有需要改進的地方
- 改善使用者體驗
- 投放廣告
改善使用者體驗
- Spotify 播放清單:分析用戶的收聽習慣來推測用戶喜歡什麼歌曲
- Facebook 內容過濾:依據用戶的使用習慣,顯示較多用戶喜歡/意見相近的貼文,造就同溫層的產生 (如果使用不當會被用來帶風向或是操控使用者的想法)
投放廣告 (以 Google 為例)
我們每天用的 Chrome、Gmail、Android、Google 搜尋引擎都是 Google 搜集使用者資料的工具
很多網站會使用 Google Analytics 來分析用戶流量和使用習慣
利用 Google Ads 和 Adsense 來結合廣告商和廣告投放平台
Google 會透過眾多搜集到的資料,分析使用者的偏好來找出對使用者效益較高的廣告來進行投放以達到最大效益
Google 在 2019 的廣告營收為 1348 億美金,佔了公司總營收的 70% (Source: Statista - Advertising revenue of Google from 2001 to 2019)
Google 搜集使用者資訊來投放廣告不是一件錯的事,身為使用者我們應該想的是我們願不願意用自己的隱私換取這些免費的服務
匿名化
分享我們的使用資訊事可以幫助產品/服務的改善,但當我們不想在分享資訊的同時失去隱私的話可以透過匿名化這個動作。這邊介紹匿名化的兩個步驟:K-匿名化 和 L-多樣化
K-匿名化 K-Anonymity
- 將資料隱藏在其他相似資料中的方法
- 一組資料中的任何一人,必須至少與(K-1)個人有相同屬性
- K 值越大,匿名性越高
L-多樣性 L-Diversity
- K-匿名化的延伸
- 確保匿名化的資料有一定的多樣性 → 避免間接指認出資料
- 一組資料中的敏感資訊應該至少有 L 種不同類型
- L 值越大,多樣性(匿名性)越高
實例 - 員工薪資資料
原始資料

在原始資料中,我們可以透過知道其中一到兩項資訊,推算出其他的資訊
Ex 1:如果知道薪水為 64,000,我們就可以知道他是女性,生日為 2/28/76,郵遞區號為 53706
Ex 2:如果知道郵遞區號為 53715 且為男性,我們就可以推算他的生日為 1/21/76,薪水為 50,000
因為這樣,我們必須對資料進行一些修改來達到匿名性
K-匿名化 (K=2)
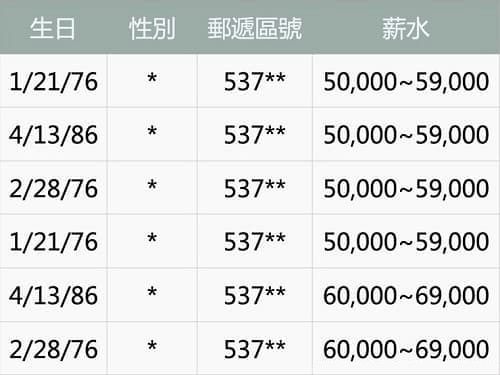
為了達到 一組資料中的任何一人,必須至少與 1(K-1)個人有相同屬性,我們需要將性別移除,並將郵遞區號和薪水兩個資訊都模糊化。
但這組資料的多樣性還不夠高,因為只要知道生日是 1/21/76 就會知道薪水區間為 50,000~59,000,雖然無法準確地知道薪水為多少,但匿名性還是不夠,因此我們需要對他進行 L-多樣性。
L-多樣性 (L=2)
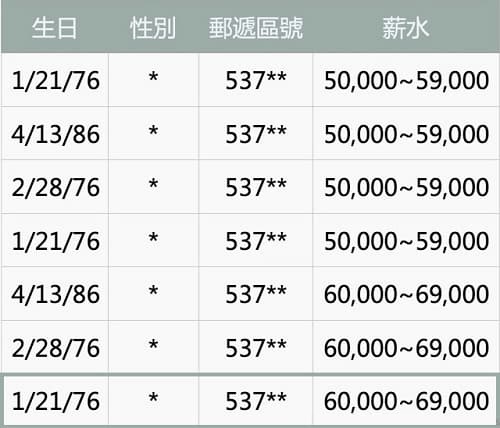
為了達到多樣性我們在資料的最後加上一筆假資料,如此一來我們便無法像先前一樣透過一兩樣資料來推算其他的資訊了。
這樣就算是達到 K=2 的 K-匿名化和 L=2 的 L-多樣性了。
增加自己隱私的小技巧/工具
前言:想要在現在的社會完全掌控自己的資訊幾乎是不可能的了,即使你沒有 Google Facebook 的帳號不用社群軟體,他們也還是會在你上網的過程中多多少少搜集到你的資訊。甚至是完全不使用網路也無法避免這件事,因此接下來教大家的方法都只能減少自己被搜集或是分享的資訊。
-
- 他是第三方組織軟體和 Facebook 分享的使用者資訊,簡單來說就是 Facebook 搜集你在其他地方的使用紀錄
- 建議大家可以把這裡面所有的紀錄都刪除,並停用 Facebook 站外動態這個功能
-
- Facebook 認為你有興趣的主題、你互動過的廣告、以及你分享的一些資料
- 建議刪除這裡面所有的東西並且選擇不分享任何資訊
-
- Facebook 為你建立一個「臉部樣板」,用於分析 Facebook 上有你在的相片及影片
- 開啟臉部辨識設定的話 Facebook 會建立樣板,並用來與其他相片、影片或其他使用相機的地方比對,來辨識你是否出現在該內容中。
- 建議關閉
-
- 是否允許 Facebook 透過行動裝置搜集定位資訊,來提供包括讓你發佈標註你所在地點的內容、瀏覽更相關的廣告、尋找附近的地標和 Wi-Fi,以及使用「周邊的朋友」等的定位相關功能。
- 建議關閉
隱私權設定檢查 設定連結
- 統整了你的定位、搜尋、應用程式活動、YouTube 等等地記錄
- 可以讓你透過日期或類型做搜尋,看自己被搜集了哪些資料
- 建議刪除這裡面所有不必要的資訊
- 建議開啟自動刪除功能,讓 Google 自動刪除就資料,有三個月或 18 月以前的資料或永不刪除三個選項
瀏覽器擴充套件 - 阻擋社群網站/廣告的追蹤
使用 VPN 來增加匿名性 (EP4 - 有必要使用 VPN 嗎?)
幫自己建立一個偽身分
隱私導向的搜尋引擎
- DuckDuckGo:搜尋結果由 Yahoo!、Bing 等不同搜尋引擎集結而來
- Startpage.com :搜尋結果由 Google 提供
隱私導向的瀏覽器
肉搜人的網站
建議大家在申請移除時使用 VPN 和拋棄式 Email
-
- 移除申請頁面 ,輸入 Email 後找到自己的資料,點選頁面最下方的”Remove This Record”emove This Record”,他們會將移除的連結寄信到你填的信箱,只要點信中的連結就可以完成移除申請
-
- 移除申請頁面,先在首頁找到自己的資料後,將連結複製到移除申請頁面中並輸入自己的 Email,他們會將移除的連結寄信到你填的信箱,只要點信中的連結就可以完成移除申請
總結
個資和隱私這類的東西是要在每天的日常中多注意的,沒有一個簡單的方法可以幫我們輕易的確保隱私。
這幾年大家有越來越重視網路隱私的趨勢,保護隱私的法規也越來越多,越來越嚴格,相信我們會慢慢地取回我們隱私的掌控權的。